
(İlk olarak 11 Ocak 2024’te Stanford İnsan Merkezli Yapay Zeka tarafından yayınlandı )
Yeni bir çalışma, çok çeşitli hukuki görevlerde üç popüler dil modelleri (LLM)arasında rahatsız edici ve yaygın hatalar buluyor.
Geçen yılın mayıs ayında Manhattan’lı bir avukat tüm yanlış sebeplerden dolayı meşhur oldu. Büyük ölçüde ChatGPT tarafından oluşturulan bir hukuki brifing sundu. Ve yargıç bu başvuruyu pek hoş karşılamadı. “Eşi görülmemiş bir durumu” tanımlayan yargıç, brifingin “sahte yargı kararlarıyla” dolu olduğunu kaydetti. . . sahte alıntılar ve sahte dahili alıntılar.” “ChatGPT avukatının” hikayesi bir New York Times hikayesi olarak viral hale geldi ve Baş Yargıç John Roberts’ın federal yargı hakkındaki yıllık raporunda büyük dil modellerinin (LLM’ler) “halüsinasyonlarının” rolünden yakınmasını tetikledi.
Peki bu tür yasal halüsinasyonlar gerçekten ne kadar yaygın?
Yasal Dönüşüm
Hukuk endüstrisi, ChatGPT, PaLM, Claude ve Llama gibi büyük dil modelerinin ortaya çıkmasıyla büyük bir dönüşümün eşiğinde. Milyarlarca parametreyle donatılmış bu gelişmiş modeller, yalnızca işleme değil aynı zamanda çok çeşitli konularda kapsamlı, güvenilir metinler üretme yeteneğine de sahiptir. Etkileri, yasal uygulamalardaki artan kullanımları da dahil olmak üzere, günlük yaşamın çeşitli yönlerinde daha belirgin hale geliyor.
Baş döndürücü sayıda hukuk teknolojisi startup’ı ve hukuk firması artık ilgili kanıtları bulmak için keşif belgelerini incelemek, ayrıntılı yasal notlar ve dava özetleri hazırlamak ve karmaşık dava stratejileri formüle etmek gibi çeşitli görevler için LLM tabanlı araçların reklamını yapıyor ve bunlardan yararlanıyor. LLM geliştiricileri gururla modellerinin baro sınavını geçebileceğini iddia ediyor.
Ancak temel bir sorun varlığını sürdürüyor: halüsinasyonlar veya Yüksek Lisans’ların gerçek yasal gerçeklerden veya köklü yasal ilkelerden ve önceliklerden sapan içerik üretme eğilimi.
Şimdiye kadar, yasal halüsinasyonların boyutuna ilişkin kanıtlar büyük ölçüde anekdot niteliğindeydi. Ancak hukuk sistemi bu tür halüsinasyonların kapsamını ve doğasını sistematik olarak incelemek için benzersiz bir pencere de sağlıyor.
Stanford RegLab ve İnsan Merkezli Yapay Zeka Enstitüsü araştırmacıları tarafından yapılan bir çalışmada, hukuki halüsinasyonların yaygın ve rahatsız edici olduğunu ortaya koyuyor: halüsinasyon oranları, %69 ile %88 arasında değişmektedir. Dahası, bu modeller sıklıkla kendi hataları konusunda farkındalıktan yoksundur ve yanlış yasal varsayımları ve inançları güçlendirme eğilimindedir. Bu bulgular, hukuksal bağlamda Yüksek Lisans’ın güvenilirliğine ilişkin önemli endişeleri gündeme getirerek, bu yapay zeka teknolojilerinin hukuki uygulamaya dikkatli ve denetimli entegrasyonunun önemini vurgulamaktadır.
Halüsinasyonun Bağlantıları
Halüsinasyon oranları, çok çeşitli doğrulanabilir yasal gerçekler açısından endişe verici derecede yüksektir. Ancak ABD hukuk sisteminin benzersiz yapısı (hiyerarşi ve otoritenin açık bir şekilde tanımlanmasıyla birlikte) halüsinasyon oranlarının temel boyutlara göre nasıl değiştiğini anlamamıza da olanak sağladı. Çalışmamızı, modellere bir görüşün yazarı gibi basit sorular sormaktan, hukuki muhakemenin temel unsuru olan iki davanın birbiriyle gerilimli olup olmadığı gibi daha karmaşık taleplere kadar uzanan bir dizi farklı görev oluşturarak tasarladık. GPT 3.5, Llama 2 ve PaLM 2’nin her birine karşı 200.000’den fazla sorguyu temel boyutlara göre atmanlandırarak test ettik.
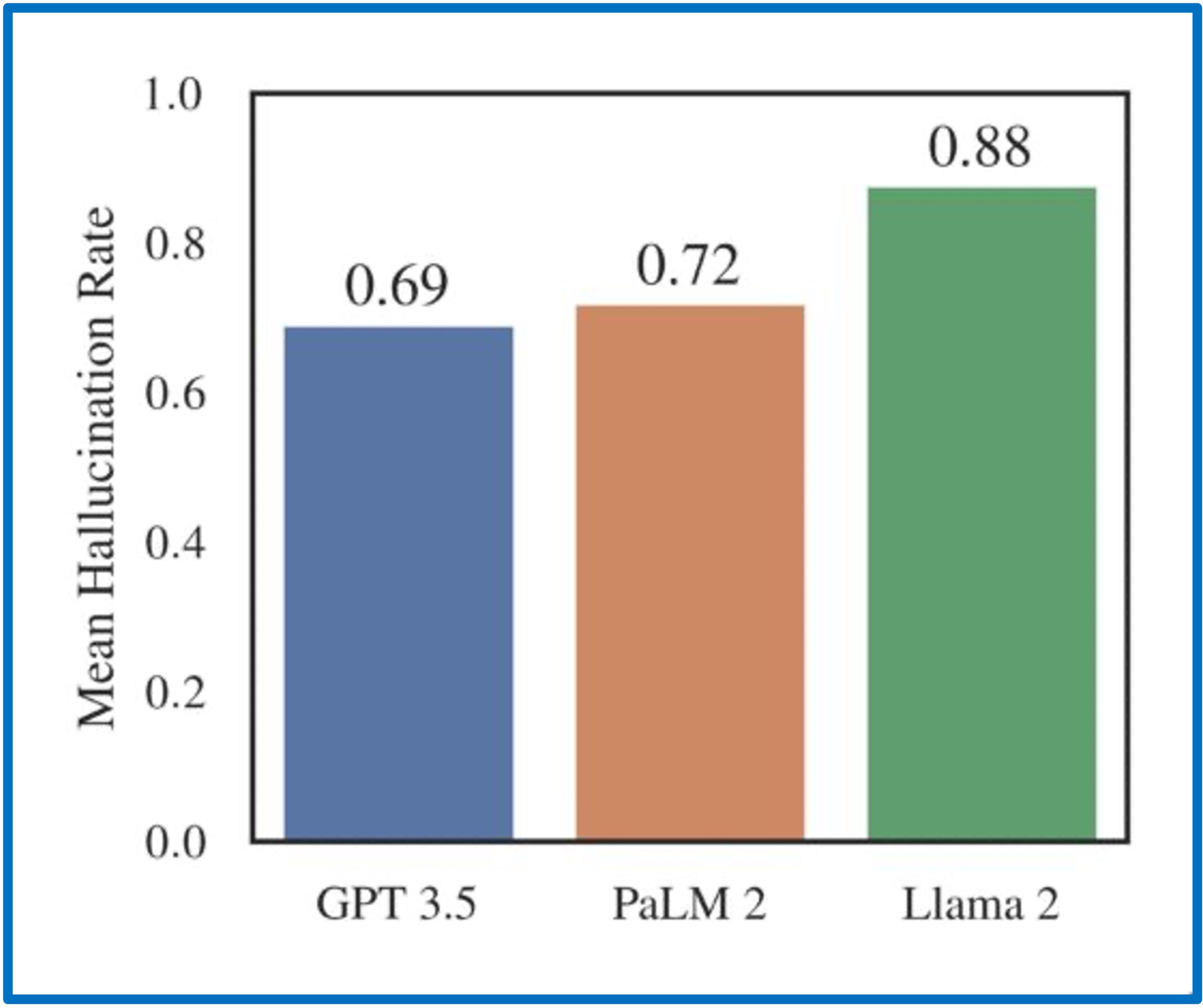
Öncelikle, hukuki konuların ayrıntılı bir şekilde anlaşılmasını veya hukuki metinlerin yorumlanmasını gerektiren daha karmaşık görevlerle uğraşırken performansın kötüleştiğini bulduk. Örneğin, iki farklı dava arasındaki emsal ilişkisini ölçen bir görevde, çoğu LLM rastgele tahminden daha iyisini yapamaz. Ve bir mahkemenin temel kararı hakkındaki soruları yanıtlarken, modeller en az %75 oranında halüsinasyon görür.
Bölge mahkemeleri gibi alt mahkemelerin içtihatları, Yüksek Mahkeme gibi yüksek mahkemelerin içtihatlarına göre daha sık halüsinasyonlara maruz kalmaktadır.
Yüksek Lisanslar, özellikle Yüksek Mahkeme’dekiler olmak üzere daha öne çıkan davalarda daha iyi performans gösterme eğilimindedir. Bu performans farklılıkları, belirli vakaların daha sık alıntılanıp tartışılmasından ve dolayısıyla bu modellerin eğitim verilerinde daha iyi temsil edilmesinden kaynaklanıyor olabilir.
Halüsinasyonlar Yüksek Mahkeme’nin en eski ve en yeni davaları arasında en yaygın olanıdır ve en az görüleni ise 20. yüzyılın sonlarındaki davalardır. Bu, LLM’lerin en yüksek performansının mevcut yasal doktrinin birkaç yıl gerisinde kalabileceğini ve LLM’lerin çok eski ancak hala uygulanabilir ve ilgili hukuku içselleştirmede başarısız olabileceğini göstermektedir.
Son olarak, farklı modeller değişen derecelerde doğruluk ve önyargı sergiler. Örneğin, GPT 3.5 genel olarak diğerlerinden daha iyi performans gösteriyor ancak tanınmış yargıçları veya belirli dava türlerini tercih etmek gibi belirli eğilimler gösteriyor. Örneğin, bir görüşü kimin yazdığı sorulduğunda GPT 3.5, Yargıç Joseph Story’nin gerçekte yazdığından çok daha fazla görüş yazdığını düşünme eğilimindedir.
Kanuna Yönelik Etkiler
Bu bulguların sonuçları ciddidir. Bugün LLM’in halkın hukuki tavsiye alması için kolay ve düşük maliyetli bir yol sağlayarak adalete erişimi demokratikleştireceği konusunda büyük bir heyecan var. Ancak bulgularımız, LLM’in mevcut sınırlamalarının, mevcut yasal eşitsizlikleri hafifletmek yerine daha da derinleştirme riski taşıdığını gösteriyor.
İdeal durumda, LLM’in yerelleştirilmiş yasal bilgiler sağlama, kullanıcıları yanlış yönlendirilmiş sorgularda etkili bir şekilde düzeltme ve yanıtlarını uygun güven düzeyleriyle nitelendirme konusunda başarılı olmalıdır. Ancak mevcut modellerde bu yeteneklerin bariz bir şekilde eksik olduğunu görüyoruz.
Bu nedenle, Hukuki Araştırma için LLM’in kullanmanın riskleri özellikle aşağıdakiler için yüksektir:
- Alt mahkemelerdeki veya daha az öne çıkan yargı bölgelerindeki davalar,
- Ayrıntılı veya karmaşık hukuki bilgi isteyen kişiler,
- Yanlış önermelere dayanarak sorular formüle eden kullanıcılar ve
- LLM yanıtlarının güvenilirliğinden emin olmayanlar.
Temelde, yasal LLM’den en fazla fayda sağlayacak kullanıcılar, tam olarak LLM’in hizmet verme konusunda en az donanıma sahip olduğu kullanıcılardır.
Dikkatli Bir Şekilde İlerlemek
LLM’lerde halüsinasyonları ele almak için çok sayıda aktif teknik çalışma devam etmektedir. Ancak yasal halüsinasyonları ele almak yalnızca teknik bir sorun değildir. LLM’lerin eğitim verilerine sadakat, kullanıcı istemlerine yanıt vermede doğruluk ve gerçek dünya yasal gerçeklerine uyum arasında denge kurmada temel uzlaşmalarla karşı karşıya olduğunu öne sürüyoruz.
Bu nedenle, halüsinasyonları en aza indirmek nihayetinde hangi tür davranışın en önemli olduğu konusunda normatif yargılar gerektirir ve bu dengeleme kararlarında şeffaflık kritik öneme sahiptir.
Yüksek Lisans’lar hukuk uygulamaları için önemli bir potansiyele sahip olsa da, çalışmamızda belgelediğimiz sınırlamalar ciddi bir dikkat gerektirmektedir. Yapay zekanın hukuk pratiğine sorumlu bir şekilde entegre edilmesi, daha fazla yinelemeyi, denetimi ve yapay zeka yetenekleri ve sınırlamalarının insan tarafından anlaşılmasını gerektirecektir.
Bu bağlamda, bulgularımız insan merkezli yapay zekanın merkeziliğini vurgulamaktadır. Sorumlu yapay zeka entegrasyonu avukatları, müvekkilleri ve yargıçları desteklemeli ve Baş Yargıç Roberts’ın dediği gibi “hukuku insanlıktan çıkarma” riskine girmemelidir.
Matthew Dahl bir JD/Ph.D. Yale Üniversitesi öğrencisi ve Stanford RegLab’ın yüksek lisans öğrencisi üyesi.
Varun Magesh, Stanford RegLab’da araştırma görevlisidir.
Miraç Suzgun, JD/Ph.D. Stanford Üniversitesi’nde bilgisayar bilimi öğrencisi ve Stanford RegLab’da yüksek lisans öğrencisi.
Daniel E. Ho, William Benjamin Scott ve Luna M. Scott Hukuk Profesörü, Siyaset Bilimi Profesörü, Bilgisayar Bilimleri Profesörü (nezaketle), HAI Kıdemli Üyesi, SIEPR Kıdemli Üyesi ve Stanford Üniversitesi RegLab Direktörüdür. .
Not: Bu yazıda DeepL tercüme algoritması kullanılmış ve yazı revize edilmiştir.