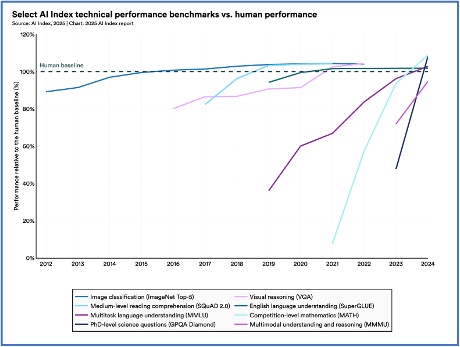
1.Yapay zeka yeni ölçütleri her zamankinden daha hızlı bir şekilde kavrıyor.
2023’te YZ araştırmacıları, giderek daha yetenekli YZ sistemlerinin sınırlarını test etmeyi amaçlayan MMMU, GPQA ve SWE-bench dahil olmak üzere birkaç zorlu yeni kıyaslama tanıttı. 2024’e kadar, bu kıyaslamalardaki YZ performansı, MMMU ve GPQA’da sırasıyla %18,8 ve %48,9 puanlık kazanımlarla dikkate değer gelişmeler gördü. SWE-bench’te, YZ sistemleri 2023’te kodlama sorunlarının yalnızca %4,4’ünü çözebildi; bu rakam 2024’te %71,7’ye yükseldi.
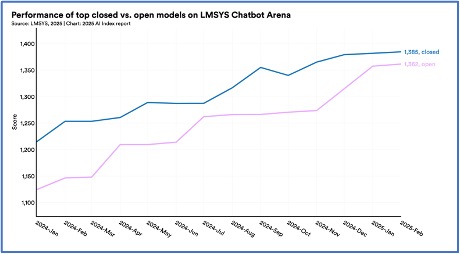
2. Açık ağırlıktaki modeller yetişiyor.
Geçtiğimiz yılki YZ Endeksi, önde gelen açık ağırlık modellerinin kapalı ağırlık emsallerinin önemli ölçüde gerisinde kaldığını ortaya koydu. 2024’e gelindiğinde bu fark neredeyse ortadan kalkmıştı. Ocak 2024’ün başlarında önde gelen kapalı ağırlık modeli, Chatbot Arena Liderlik Tablosu’nda en iyi açık ağırlık modelini %8,04 oranında geride bıraktı. Şubat 2025’e gelindiğinde bu fark %1,70’e düştü.
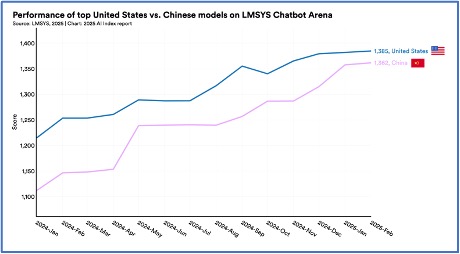
3. Çin ve ABD modelleri arasındaki fark kapanıyor.
2023’te önde gelen Amerikan modelleri Çinli rakiplerinden önemli ölçüde daha iyi performans gösterdi; bu artık geçerli olmayan bir trend. 2023’ün sonunda MMLU, MMMU, MATH ve HumanEval gibi kıyaslama ölçütlerindeki performans farkları sırasıyla 17,5, 13,5, 24,3 ve 31,6 yüzde puanıydı. 2024’ün sonunda bu farklar önemli ölçüde sadece 0,3, 8,1, 1,6 ve 3,7 yüzde puanına daraldı.
4. Yapay zeka modeli performansı sınırda birleşiyor.
Geçtiğimiz yılın YZ Endeksi’ne göre, Chatbot Arena Liderlik Tablosu’nda en üst ve 10. sıradaki model arasındaki Elo puanı farkı %11,9’du. 2025’in başlarında bu fark sadece %5,4’e düştü. Benzer şekilde, en üst iki model arasındaki fark 2023’teki %4,9’dan 2024’te sadece %0,7’ye düştü. YZ manzarası giderek daha rekabetçi hale geliyor ve artık artan sayıda geliştiriciden yüksek kaliteli modeller elde edilebiliyor.

5. Test zamanı hesaplaması gibi yeni akıl yürütme paradigmaları model performansını iyileştirir.
2024’te OpenYZ, çıktıları üzerinden yinelemeli olarak akıl yürütmek üzere tasarlanmış o1 ve o3 gibi modeller tanıttı. Bu test zamanı hesaplama yaklaşımı, o1’in Uluslararası Matematik Olimpiyatı yeterlilik sınavında GPT-4o’nun %9,3’üne kıyasla %74,4 puan almasıyla performansı önemli ölçüde iyileştirdi. Ancak, bu geliştirilmiş akıl yürütmenin bir bedeli var: o1, GPT-4o’dan neredeyse altı kat daha pahalı ve 30 kat daha yavaş.
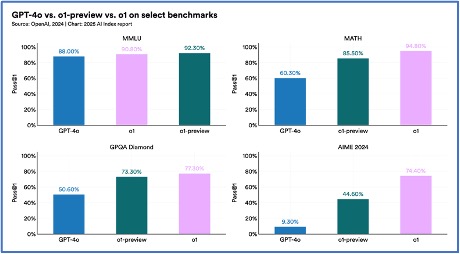
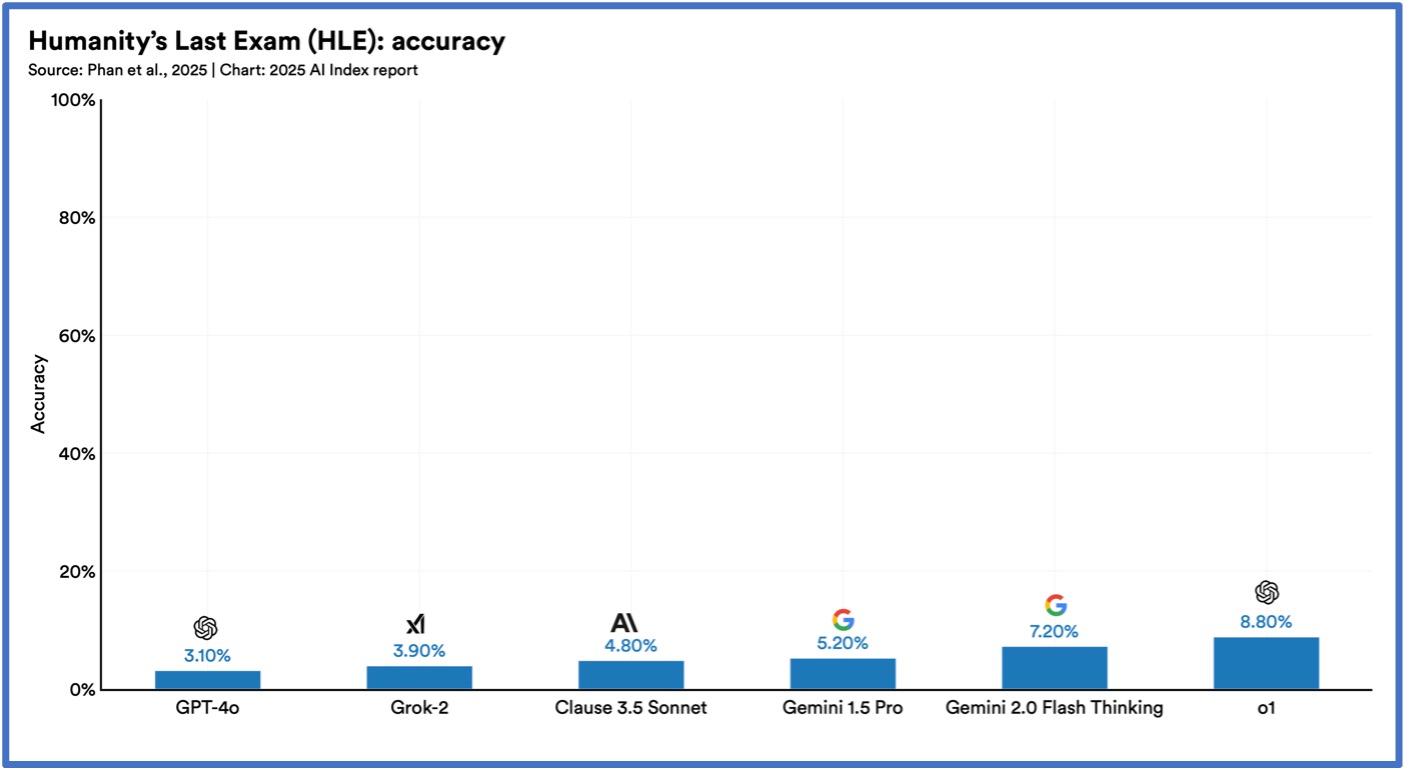
6. Sürekli olarak daha zorlayıcı ölçütler önerilmektedir.
MMLU, GSM8K ve HumanEval gibi geleneksel YZ kıyaslamalarının doygunluğu, MMMU ve GPQA gibi daha yeni ve daha zorlu kıyaslamalarda iyileştirilmiş performansla birleştiğinde, araştırmacıları önde gelen YZ sistemleri için ek değerlendirme yöntemleri keşfetmeye itti. Bunlar arasında en dikkat çekenler, en iyi sistemin sadece %8,80 puan aldığı zorlu bir akademik sınav olan Humanity’s Last Exam; YZ sistemlerinin problemlerin sadece %2’sini çözdüğü karmaşık bir matematik kıyaslaması olan FrontierMath; ve YZ sistemlerinin %35,5 başarı oranına ulaştığı bir kodlama kıyaslaması olan BigCodeBench’tir; bu, %97’lik insan standardının çok altındadır.
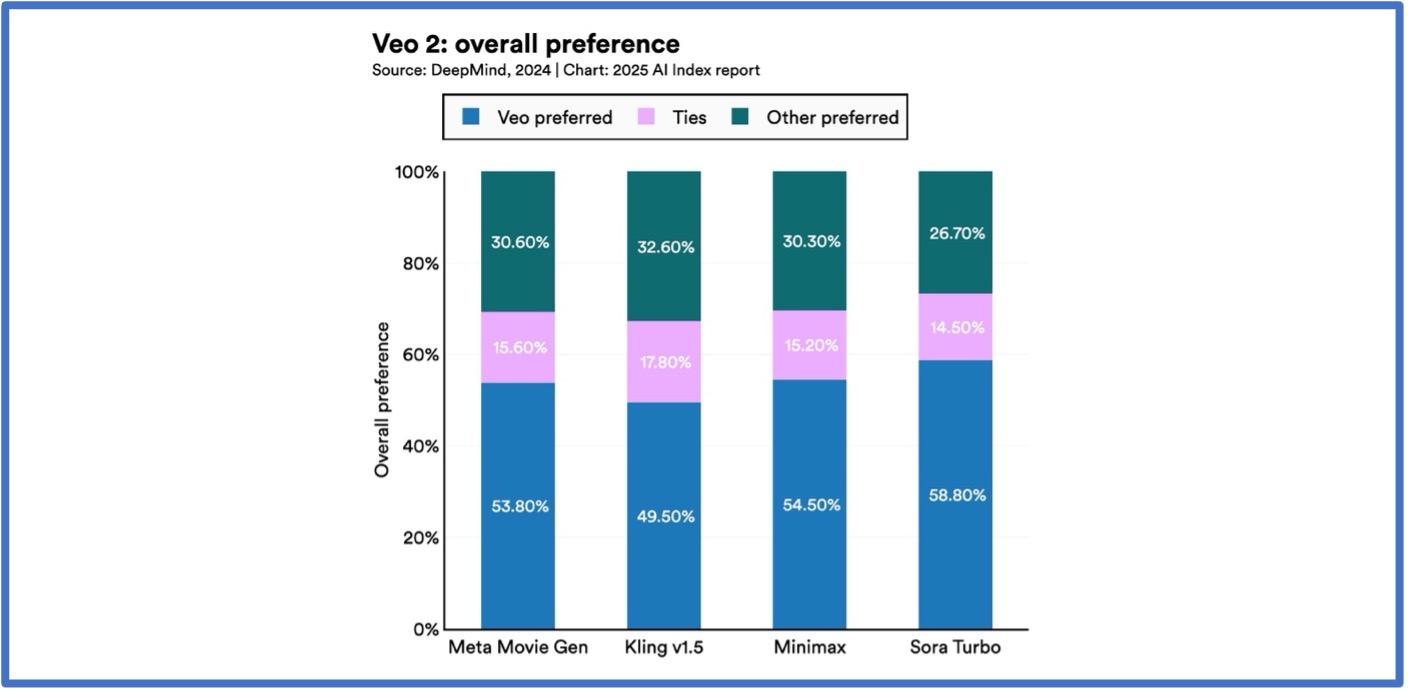
7. Yüksek kaliteli yapay zeka video üreteçleri önemli iyileştirmeler gösteriyor.
2024’te, metin girdilerinden yüksek kaliteli videolar üretebilen birkaç gelişmiş YZ modeli piyasaya sürüldü. Önemli sürümler arasında OpenYZ’nin SORA’sı, Stable Video Diffusion 3D ve 4D, Meta’nın Movie Gen’i ve Google DeepMind’ın Veo 2’si yer aldı. Bu modeller, 2023’tekilere kıyasla önemli ölçüde daha yüksek kalitede videolar üretti.
8. Daha küçük modeller daha güçlü performans sağlar.
2022’de MMLU’da %60’tan yüksek bir puan kaydeden en küçük model 540 milyar parametreyle PaLM oldu. 2024’e gelindiğinde Microsoft’un sadece 3,8 milyar parametreli Phi-3-mini’si aynı eşiğe ulaştı. Bu, iki yılda 142 katlık bir azalmayı temsil ediyor.

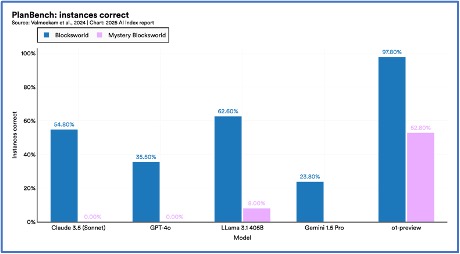
9. Karmaşık muhakeme sorunu devam ediyor.
Düşünce zinciri muhakemesi gibi mekanizmaların eklenmesi LLM’lerin performansını önemli ölçüde iyileştirmiş olsa da, bu sistemler hala aritmetik ve planlama gibi mantıksal muhakeme kullanılarak kanıtlanabilir şekilde doğru çözümler bulunabilen sorunları güvenilir bir şekilde çözemez, özellikle de eğitim aldıkları örneklerden daha büyük örneklerde. Bunun bu sistemlerin güvenilirliği ve yüksek riskli uygulamalardaki uygunluğu üzerinde önemli bir etkisi vardır.
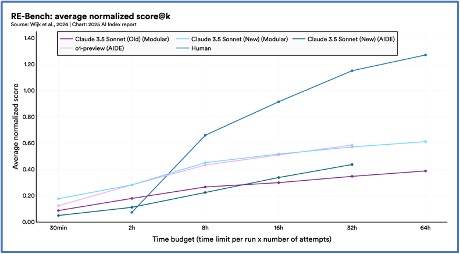
10. Yapay zeka ajanları erken dönemde umut vadediyor.
2024’te RE-Bench’in piyasaya sürülmesi, YZ ajanları için karmaşık görevleri değerlendirmek için titiz bir kıyaslama getirdi. Kısa zaman ufku ayarlarında (iki saatlik bütçe), en iyi YZ sistemleri insan uzmanlarından dört kat daha yüksek puan alır, ancak zaman bütçesi arttıkça, insan performansı YZ’yı geride bırakır ve 32 saatte iki kat daha fazla puan alır. YZ ajanları, Triton çekirdekleri yazmak gibi belirli görevlerde insan uzmanlığıyla zaten eşleşirken, sonuçları daha hızlı ve daha düşük maliyetlerle sunar.