
Melissa Heikkilä/Aralık 2024
Yeni bulgular, veri kaynaklarının gücün en güçlü teknoloji şirketlerinin elinde nasıl yoğunlaştığını gösteriyor.
Yapay zeka tamamen veriyle ilgilidir. Algoritmaları istediğimiz şeyi yapmaları için eğitmek için yığınlarca veriye ihtiyaç vardır ve yapay zeka modellerine girenler çıkanları belirler.
Ancak sorun şu: Yapay zeka geliştiricileri ve araştırmacıları kullandıkları verilerin kaynakları hakkında pek bir şey bilmiyorlar. Yapay zekanın veri toplama uygulamaları, yapay zeka modeli geliştirmenin karmaşıklığıyla karşılaştırıldığında olgunlaşmamış durumda. Büyük veri kümeleri genellikle içlerinde ne olduğu ve nereden geldiği hakkında net bilgilerden yoksundur.
Hem akademiden hem de endüstriden 50’den fazla araştırmacıdan oluşan bir grup olan Veri Kaynağı Girişimi bunu düzeltmek istiyordu. Çok basit bir şekilde şunu bilmek istiyorlardı: Yapay zekayı oluşturmak için gereken veriler nereden geliyor? 600’den fazla dili, 67 ülkeyi ve üç on yılı kapsayan yaklaşık 4.000 genel veri setini denetlediler. Veriler 800 benzersiz kaynaktan ve yaklaşık 700 kuruluştan geldi.
MIT Technology Review ile özel olarak paylaşılan bulguları endişe verici bir eğilimi ortaya koyuyor: Yapay zekanın veri uygulamaları, gücün büyük ölçüde birkaç baskın teknoloji şirketinin elinde yoğunlaşması riski taşıyor.
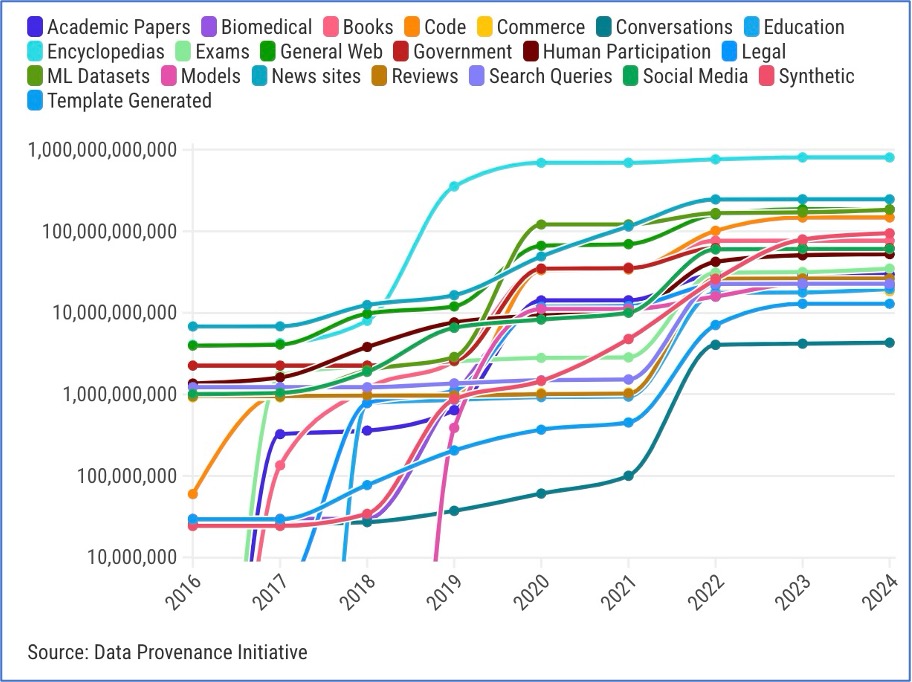
Projenin bir parçası olan MIT araştırmacısı Shayne Longpre, 2010’ların başında veri setlerinin çeşitli kaynaklardan geldiğini söylüyor.
Sadece ansiklopedilerden ve web’den değil, aynı zamanda parlamento tutanakları, kazanç çağrıları ve hava durumu raporları gibi kaynaklardan da geliyordu. O zamanlar, yapay zeka veri kümeleri, bireysel görevlere uyacak şekilde özel olarak düzenlenmiş ve farklı kaynaklardan toplanmıştı, diyor Longpre.
Daha sonra 2017’de dil modellerinin temelini oluşturan mimari olan dönüştürücüler icat edildi ve YZ sektörü, modeller ve veri kümeleri büyüdükçe performansın daha iyi hale geldiğini görmeye başladı. Günümüzde, YZ veri kümelerinin çoğu internetten ayrım gözetmeksizin materyal toplayarak oluşturuluyor. 2018’den beri web, ses, görüntü ve video gibi tüm medyalarda kullanılan veri kümeleri için baskın kaynak oldu ve kazınmış veriler ile daha fazla düzenlenmiş veri kümeleri arasında bir boşluk ortaya çıktı ve genişledi.
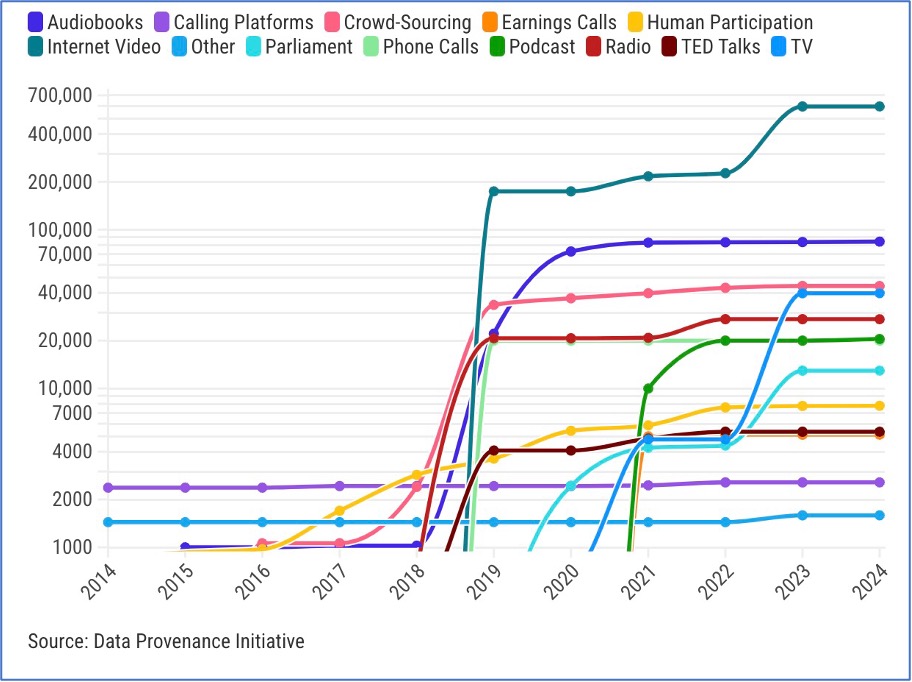
Longpre, “Temel model geliştirmede, yetenekler için verinin ve web’in ölçeği ve heterojenliğinden daha önemli bir şey yok gibi görünüyor” diyor. Ölçek ihtiyacı, sentetik verinin kullanımını da büyük ölçüde artırdı.
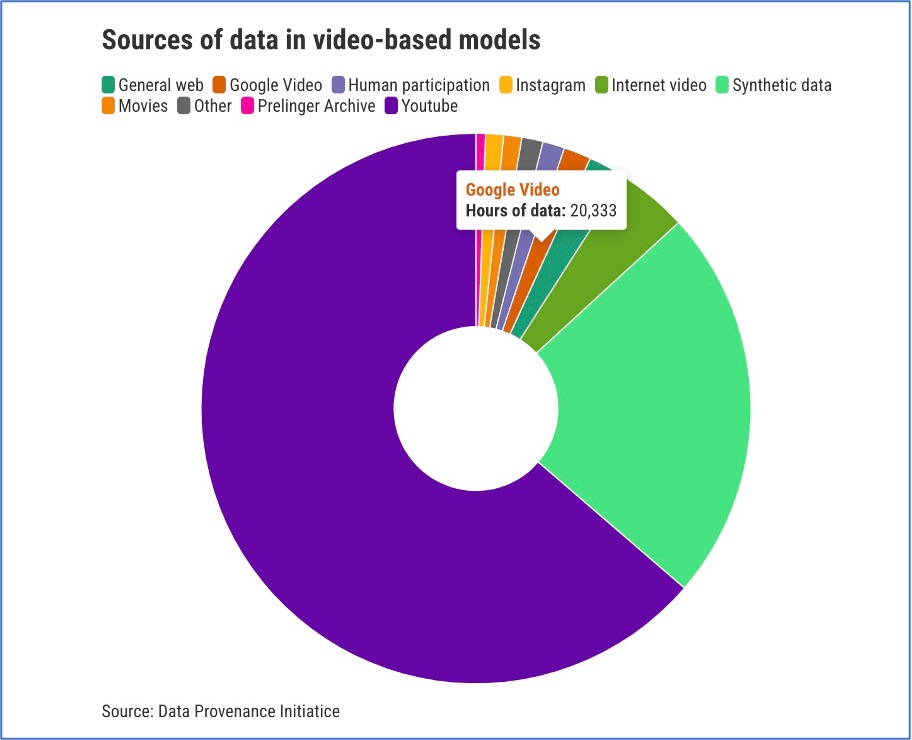
Tüm modelleri gibi, mümkün olduğunca çok veriye ihtiyaç duyarlar ve bunun için en iyi kaynak YouTube olmuştur. Son birkaç yılda ayrıca video ve görüntü üretebilen çok modlu üretken AI modelleri de yükselişe geçti. Büyük dil modelleri için, bu grafikte görebileceğiniz gibi, hem konuşma hem de görüntü veri kümelerinin verilerinin %70’inden fazlası tek bir kaynaktan geliyor.
Bu, YouTube’un sahibi olan Google’ın ana şirketi Alphabet için bir nimet olabilir. Metin web genelinde dağıtılırken ve birçok farklı web sitesi ve platform tarafından kontrol edilirken, video verileri tek bir platformda aşırı derecede yoğunlaşmıştır.
Longpre, “Bu durum, web üzerindeki en önemli verilerin birçoğu üzerinde büyük bir güç yoğunluğunun tek bir şirkette toplanmasını sağlıyor” diyor.
YZ Now Enstitüsü’nün eş yöneticisi Sarah Myers West, Google’ın kendi yapay zeka modellerini de geliştirmesi nedeniyle, bu büyük avantajın şirketin bu verileri rakipleriyle nasıl paylaşacağı konusunda soruları da gündeme getirdiğini söylüyor.
Myers West, “Verileri doğal olarak oluşan bir kaynak olarak düşünmekten ziyade, belirli süreçlerle yaratılan bir şey olarak düşünmek önemlidir” diyor.
“Etkileşimde bulunduğumuz yapay zekaların çoğunun kullandığı veri kümeleri, büyük, kâr odaklı şirketlerin niyetlerini ve tasarımlarını yansıtıyorsa, bu, dünyamızın altyapılarını bu büyük şirketlerin çıkarlarını yansıtacak şekilde yeniden şekillendiriyor demektir” diyor.
Teknoloji şirketi Cohere’nin araştırma başkan yardımcısı ve aynı zamanda Veri Kaynağı Girişimi’nin bir parçası olan Sara Hooker, bu tek kültürün aynı zamanda veri setinde insan deneyiminin ne kadar doğru şekilde tasvir edildiği ve ne tür modeller oluşturduğumuz konusunda da sorular ortaya çıkardığını söylüyor.
İnsanlar YouTube’a belirli bir kitleyi düşünerek video yüklüyor ve insanların bu videolardaki hareket biçimleri genellikle çok belirli bir etki yaratmayı amaçlıyor. Hooker, “[Veriler] insanlığın tüm nüanslarını ve var olduğumuz tüm yolları yakalıyor mu?” diyor.
Gizli kısıtlamalar:
Yapay zeka şirketleri genellikle modellerini eğitmek için kullandıkları verileri paylaşmazlar. Bunun bir nedeni rekabet avantajlarını korumak istemeleridir. Diğeri ise veri kümelerinin paketlenmesi, ambalajlanması ve dağıtılmasının karmaşık ve opak yolu nedeniyle, muhtemelen tüm verilerin nereden geldiğini bile bilmiyorlardır.
Ayrıca, bu verilerin nasıl kullanılacağı veya paylaşılacağı konusunda herhangi bir kısıtlama hakkında muhtemelen tam bilgiye sahip değillerdir. Data Provenance Initiative’deki araştırmacılar, veri kümelerinin genellikle kısıtlayıcı lisanslara veya bunlara bağlı şartlara sahip olduğunu ve bu durumun örneğin ticari amaçlar için kullanımını sınırlaması gerektiğini buldular.
Hooker, “Veri soy hattındaki bu tutarsızlık, geliştiricilerin hangi verileri kullanacakları konusunda doğru seçimi yapmalarını çok zorlaştırıyor” diyor.
Longpre, ayrıca modelinizi telif hakkıyla korunan veriler üzerinde eğitmediğinizden tamamen emin olmanın neredeyse imkansız hale geldiğini de sözlerine ekliyor.
Daha yakın zamanda, OpenAI ve Google gibi şirketler yayıncılar, Reddit gibi büyük forumlar ve web’deki sosyal medya platformlarıyla özel veri paylaşım anlaşmaları yaptı. Ancak bu, güçlerini yoğunlaştırmanın başka bir yolu haline geliyor.
Longpre, “Bu özel sözleşmeler interneti, kimlerin erişebileceği ve kimlerin erişemeyeceği şekilde çeşitli bölgelere bölebilir” diyor.
Bu eğilim, araştırmacılar, kâr amacı gütmeyen kuruluşlar ve erişim sağlamakta zorluk çekecek daha küçük şirketler pahasına, bu tür anlaşmaları karşılayabilen en büyük YZ oyuncularına fayda sağlıyor. En büyük şirketler ayrıca veri kümelerini taramak için en iyi kaynaklara sahip.
Longpre, “Bu, açık web’de bu ölçüde görmediğimiz yeni bir asimetrik erişim dalgası” diyor.
Batı vs. geri kalanlar.
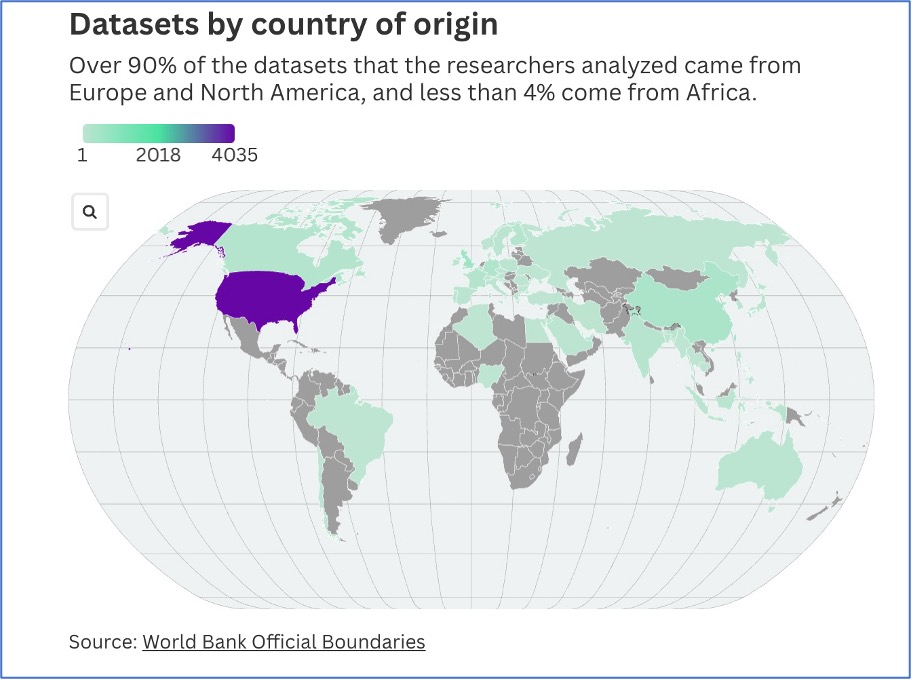
Yapay zeka modellerini eğitmek için kullanılan veriler de Batı dünyasına oldukça fazla eğilimlidir. Araştırmacıların analiz ettiği veri kümelerinin %90’ından fazlası Avrupa ve Kuzey Amerika’dan, %4’ten azı ise Afrika’dan geldi.
Hooker, “Bu veri kümeleri dünyamızın ve kültürümüzün bir bölümünü yansıtıyor, ancak diğerlerini tamamen göz ardı ediyor” diyor.
Eğitim verilerinde İngilizce dilinin baskınlığı kısmen internetin hala %90’dan fazlasının İngilizce olması ve Dünya’da hala çok sayıda yerde internet bağlantısının gerçekten zayıf olması veya hiç olmaması gerçeğiyle açıklanıyor, diyor araştırma ekibinde yer almayan Hugging Face’in baş etikçisi Giada Pistilli. Ancak bir diğer nedenin de kolaylık olduğunu ekliyor: Diğer dillerde veri kümeleri oluşturmak ve diğer kültürleri hesaba katmak bilinçli niyet ve çok fazla çalışma gerektiriyor.
Bu veri kümelerinin Batı odaklılığı, özellikle çok modlu modellerde belirginleşiyor. Örneğin, bir YZ modeline bir düğünün görüntüleri ve sesleri sorulduğunda, yalnızca Batı düğünlerini temsil edebilir, çünkü eğitildiği tek şey bu, diyor Hooker.
Bu durum önyargıları güçlendirir ve belirli bir ABD merkezli dünya görüşünü dayatarak diğer dilleri ve kültürleri yok eden yapay zeka modellerine yol açabilir.
Hooker, “Bu modelleri dünyanın her yerinde kullanıyoruz ve gördüğümüz dünya ile bu modellerin göremediği dünya arasında çok büyük bir tutarsızlık var” diyor.
https://www.technologyreview.com/2024/12/18/1108796/this-is-where-the-data-to-build-ai-comes-from/